KI-Coding: Der Untergang der IT?
Künstliche Intelligenz hat die Softwareentwicklung spürbar verändert. Moderne AI-Coding-Tools können Code generieren, Tests schreiben und bei der Problemanalyse unterstützen. Richtig eingesetzt beschleunigen sie die tägliche Arbeit erheblich. Falsch eingesetzt, können sie jedoch zu schwerwiegenden technischen und architektonischen Fehlentscheidungen führen.
Uneinigkeit bei Forschenden und Entwicklern
Es gibt eine Menge wissenschaftliche Studien, die sich mit der Frage beschäftigen, wie KI beim Coden eingesetzt werden kann und welche Vorteile die Nutzung bringt. Und die Antwort ist ganz klar: Keiner weiß es.
Die Meinungen unter den Forschenden wie auch unter den Entwicklern selbst gehen weit auseinander. Shethiya schreibt im Journal “Annals of Applied Sciences“, dass AI-Assistance wie Github Copilot die Effizienz erhöht, technical debt reduziert und die Software Security verbessert, und zitiert dabei mehrere Studien. Zur Effizienzsteigerung werden besonders die Bugfixing-Fähigkeiten hervorgehoben, wie auch die Möglichkeit, mittels AI Best Practices zu garantieren. [3, S. 6f]
Fu u. a. dagegen haben automatisch generierte Code Snippets von mehreren Github-Projekten untersucht und kommen zu dem Ergebnis, dass 25-30% aller Python- und JavaScript-Frontends, die automatisch generiert wurden, IT-Sicherheitsprobleme hatten. Ein Großteil wurde in Warnungen ausgegeben (z. B. beim Testen). Nachdem Copilot die Warnungen gegeben hatte, korrigierte der etwa 55,5 % der Fehler.[5]
Auch wenn sich die beiden Forschungen nicht zwingend widersprechen (Erste geht von einer Nutzung von AI durch Entwickler aus, letztere geht von einer reinen Code-Generation aus), zeigt dies doch, dass mit AI weder alles möglich ist noch dass sie keinen Effizienzgewinn erzielen kann. Viele weitere Studien zeigen, dass die Meinungen weit auseinanderliegen. Einige behaupten, die Qualität leide nicht und es gehe schneller; andere Studien kommen zu dem Ergebnis, dass die Qualität leide.[1]
Die Wahrheit liegt dazwischen.
Mit KI können Entwickler*innen repetitive Aufgaben schneller erledigen, erste Implementierungen in kurzer Zeit umsetzen und sich stärker auf intellektuell fordernde Fragestellungen konzentrieren. Besonders bei Standardaufgaben oder bekannten Mustern liefert KI in Sekunden Ergebnisse, für die man früher deutlich länger gebraucht hätte.
Das legt auch eine Studie zur Verwendung von Chatbots nahe: Entwickler nutzen Chatbots um Aufgaben zu erledigen, auf die sie selber keine Lust haben. Tests schreiben und Dokumentation zum Beispiel.[2]
Diese schnellen Ergebnisse müssen jedoch stets von erfahrenen Fachleuten geprüft werden. KI versteht weder die Geschäftslogik noch die langfristigen Wartungsanforderungen noch die Systemverantwortung. Eine spezielle Schwäche, die beim verwenden von AI-Systemen oft auffällt, ist das fehlender Kontext oft frei interpretiert wird und operiert so aufgrund von falschen Annahmen: An einer Stelle wird eine Lösung erarbeitet, die für die Aufgabe, die sie lösen soll, zu komplex ist; an anderer Stelle ist die Lösung zu simpel eingebaut.
Ein Beispiel:
Wir wollen ein Spiel mit Freunden und Gegnern bauen. An sich sind das beides Wesen, die gemeinsame Eigenschaften haben (z. B. sich bewegen, springen, Lebenspunkte haben etc.). Sie können Eigenschaften wiederverwenden und mit einer generelleren Wesen-Klasse voneinander erben. Weil wir dem Chatbot aber erst den Auftrag gaben, Gegner zu erstellen, erstellte es also eine Klasse Gegner, ohne zu bedenken, dass es diese Korrelation geben könnte. Erst wenn wir Freunde erstellen lassen, fällt auf, dass auch Freunde Eigenschaften von Gegnern haben. Heißt, es gibt jetzt eine Freunde-Klasse, die von Wesen erbt, und eine Gegner-Klasse, die das nicht tut, was den Code inconsistent macht und ihn langfristig nicht maintainable macht.
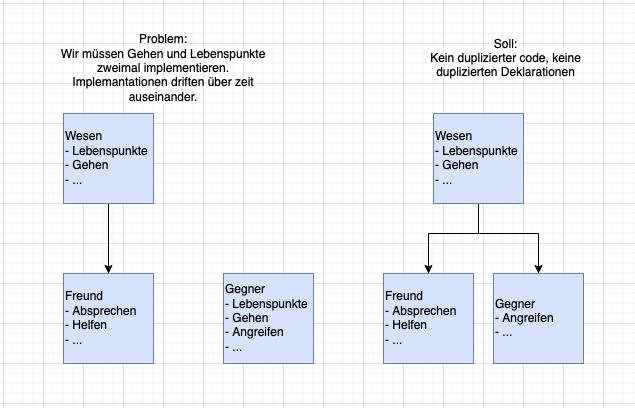
Abb.: Stückweise Generierung, vs gesamtheitliches Konzept
Beim Prompten, wie auch beim überprüfen der Lösung darf also der Blick auf das große Ganze nicht fehlen.
Das zeigt auch, dass Vorkenntnisse erforderlich sind, um das Tool richtig einzusetzen. Eine weitere Studie mit einer existierenden Codebase zeigt, dass Junioren zwar ebenfalls schneller mit AI zum Ziel kommen, sich aber anschließend nicht sicher sind, ob sie etwas dabei gelernt haben.[4]
Dennoch können Sie KI nutzen, um mehr Verständnis zu gewinnen. Denn ein häufiger Zweck von Coding-Chatbots ist das Codeverständnis. Eine Umfrage von Weisz u. a. kam auf, dass der häufigste Use Case für die Befragten Codeverständnisfragen war. Sie nannten das “Exploration Mode“ und die Unterstützung beim Weiterentwickeln “Acceleration Mode“.[1]
KI mit Handführung ein Programm bauen lassen
KI ist besonders stark in klar definierten, gut strukturierten Aufgaben:
Testing: Unitests sind kein Problem, wenn der AI das File gegeben wird. Größere Integration Tests sind auch kein Problem, wenn der AI direkt gezeigt wird, wie die aussehen sollen und was die Expectations der Testfälle sind.
Arbeiten mit klaren Anweisungen: Offene Punkte vermeiden, je direkter desto besser. Beispielsweise Cloude Opus ist zuletzt deutlich besser mit dem Interpretieren geworden und kann auch aus den Kontext heraus erschließen, was genau zu tun ist.
Aufzeigen von Optionen: KI kann verschiedene Lösungsansätze oder Implementierungsvarianten vorschlagen und so Entscheidungsprozesse unterstützen. Eine Bewertung, welche Vorschläge am besten sind, sollte jedoch von den Entwickler*innen selbst vorgenommen werden.
In diesen Bereichen ist KI ein wertvolles Werkzeug – ein digitaler Assistent, der zuarbeitet, beschleunigt und entlastet.
Ein gefährlicher Fehler: Architekturentscheidungen an KI delegieren
Ein häufiger und kritischer Fehler besteht darin, architektonische Entscheidungen der KI zu überlassen. Systemarchitektur erfordert Erfahrung, Kontextwissen und ein Verständnis für zukünftige Anforderungen. Die KI kennt oder nutzt dieses Kontextwissen jedoch nicht immer.
Wer Architektur von der KI entwerfen lässt, riskiert:
unnötige Komplexität
schlechte Skalierbarkeit
schwer wartbare Systeme
Sicherheits- und Performanceprobleme
Gerade bei architektonischen Entscheidungen greift die KI weniger auf Expertise und viel mehr auf die allgemeine Meinung aus dem Internet zurück. Das Tolle an der IT ist, dass jedes Problem einzigartig ist. Es gibt zwar sehr viele Programming-Patterns, die den Großteil der Probleme lösen, aber welches Pattern das richtige ist, ist eine Frage, bei der oft auch die Meinung der Entwickler*innen auseinandergeht. Aus diesem Gemenge an Meinungen kann es dazu kommen, dass die KI die falsche Lösung vorschlägt, diese dann aber auch nach mehrmaligem Nachhaken verteidigt.
Noch gefährlicher: KI nutzen, ohne nachzudenken
Der größte Fehler ist nicht die Nutzung von KI, sondern die unkritische Verwendung. Nach der Generierung des Codes muss überprüft werden, ob er das macht, was er machen soll. Ob der Code klar und verständlich ist und wie der neue Code im Zusammenhang mit weiteren Aufgaben und Anforderungen an den Code steht. Deshalb ist Testing gut geeignet für AI: In der Regel gibt es keine weiteren Anforderungen als das Testen des Codes, und es besteht auch keine Möglichkeit, dass neue Entwicklungen auf Unit-Tests aufbauen.
Man kann sich auch außerhalb der Code-Generierung Vorschläge zu Lösungen gröberer Probleme und zu Bugfixes erarbeiten lassen, auch wenn ich damit nur mittelmäßig gute Erfahrungen gemacht habe. Man sollte beim Diskutieren mit dem Chatbot jedoch darauf schauen, ob es gerade festhängt und auch nach mehreren Prompt-Versuchen der Lösung nicht näher kommt. Viel zu oft schlägt es die gleichen, oder ähnlichen Lösungen für die gleichen Probleme vor - wurde eine Lösung für einen Teil der Probleme gefunden, wird sie mit dem nächsten Prompt fälschlicherweise wieder rausgeworfen. Rechtzeitig realisieren, wenn der Chatbot nicht weiterkommt, bei jedem Schritt prüfen, ob die Lösung das Problem lösen kann und regelmäßig gute Lösungen commiten, um notfalls von schlechten Lösungen zurückzurollen, hilft hier sehr.
Der Chatbot hinterfragt die Nutzer*innen nicht oder nur sehr selten und ist viel zu stark auf die Bestätigung der Nutzer*innen ausgerichtet. Deshalb müssen die Nutzer*innen sich selbst kritisch hinterfragen.
Best Case: Klare lückenlose Prompts & kritische Prüfung
Hiermit konnte ich Claude Opus 4.5 spontan ein tic-tac-toe spiel bauen lassen:
“Create a project for a tic-tac-toe webpage. The user plays against the AI, clicking first on an available field. User takes X as a symbol, and AI takes O as a symbol. Keep the AI logic simple; use random placement if necessary. Use React frontend.“
Die Anforderungen klingen relativ grob - sind sie auch. Aber, so eine Aufgabe wurde Claude Opus schon Millionen mal gestellt, also meistert es die Aufgabe Problemfrei. Der Code ist verständlich, auch wenn es derzeit nur lokal deployed ist. Ich schreibe dem Bot, dass er noch das Spiel Schiffe versenken hinzufügen soll. Das Ergebnis funktioniert wieder einwandfrei, aber es befindet sich nun alles in einem app.jsx file, was nun unübersichtlich wird. Also bitte ich in einem dritten Prompt das ganze zu trennen, was wieder einwandfrei funktionierte.
Alles was ich nicht angegeben habe, wurde frei interpretiert: Schiffe werden zufällig für AI und User platziert und die AI entscheided wieder basierend auf Zufall, wo sie hinschießen soll, womit ihre Strategie der meinigen immerhin ebenwürdig ist… Das Hauptmenü, wo der Nutzer zwischen den Spielen entscheided ist abgebildet mit freien Strings, wo wahrscheinlich ein enum besser wäre.
Im großen und ganzen ist die Basis jedoch solide und funktionabel.
Ich habe auch gegenteilige Erfahrungen gemacht. In einem Projekt ging es darum, Objekte im Weltraum aus Sicht eines Spielers korrekt darzustellen. Dabei ist wichtig, dass man berücksichtigt, dass Licht Zeit braucht, um beim Spieler anzukommen. Ein Objekt wird also nicht dort gesehen, wo es „jetzt“ ist, sondern dort, wo es war, als das Licht ausgesendet wurde. Der Server berechnete bereits die echten Positionen aller Objekte, aber es musste noch berechnet werden, wann und wo ein Objekt für den jeweiligen Spieler sichtbar wird und wie es sich aus dessen Sicht bewegt.
Nach einigen Versuchen wurde das mathematisch korrekt gelöst, inklusive Effekten wie Relativgeschwindigkeit und Dopplereffekt. Das Problem war jedoch:
Diese Berechnung wurde vom Bot auf der Client-Seite eingefügt. Als sich Server und Client synchronisieren sollten, kam es zu starken Sprüngen („Snapping“) der Objekte, weil Server und Client leicht unterschiedliche Ergebnisse berechneten. Der Chatbot bestand trotzdem darauf, die Berechnung beim Client zu lassen, da dies besser zum Konzept „berechnen der Position relativ zum Beobachter (=Client)“ passe.
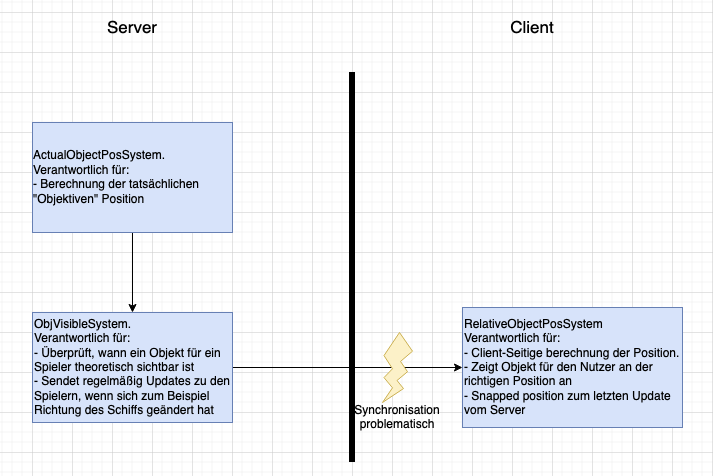
Abb.: Von Claude Opus generierte Lösung (Vereinfachte Darstellung)
Das ist aber nicht möglich, da Server und Client immer zwangsläufig auseinander laufen würden. Erst als explizit vorgegeben wurde, dass die Berechnung vollständig auf dem Server stattfinden muss, wurde das Problem schrittweise korrekt gelöst.
Die Entwickler*innen müssen erkennen können, wann ein Chatbot einer theoretisch sauberen Idee folgt, die praktisch nicht funktionieren, und wann der generierte Code wirklich die Anforderungen erfüllt. Ebenso wichtig ist die Erfahrung, Prompts so zu formulieren, dass der Chatbot nicht an einer falschen Annahme festhält.
Wenn man das befolgt, kann man relativ schnell Großes schaffen. Selbst mit spezifischen Frameworks, die nicht weit verbreitet sind, wie Entity-Component-Systeme in der relativ neuen Bevy-Engine, hat die AI keine Probleme, neue Systeme und Funktionen hinzuzufügen.
Fazit
Entwickler*innen denken voran; die AI setzt um; Entwickler*innen überprüfen die Ergebnisse. Dieser Dreisatz scheint der derzeitige Stand der Dinge zu sein.
In einer Studie wurde mit GitHub Copilot 1.7.442 gezeigt, dass Entwickler*innen 55 % schneller arbeiten als ohne Copilot, ohne dass die Code-Qualität leidet oder die Test-Coverage sinkt. Im Gegenteil, beides ist gestiegen.[6]
Beim Verwenden sollte immer überprüft werden, ob der generierte Code funktioniert und ob alle test-cases abgedeckt sind. Beim Schreiben der Prompts sollte darauf geachtet werden, keine relevanten Anforderungen auszulassen. Diese werden von der KI frei interpretiert, was in der Regel zu falsch produziertem Code führt, der anschließend händisch gedebuggt werden muss.
Quellenangaben:
[1] Weisz, Justin D. u. a. (2025): https://dl.acm.org/doi/full/10.1145/3706599.3706670#Bib0013
[2] Sergeyuk, Agnia u.a. (2025): https://www.sciencedirect.com/science/article/abs/pii/S0950584924002155
[3] Shethiya, Aditya S. (2025): https://annalsofappliedsciences.com/index.php/aas/article/view/15
[4] Shihab, Istiak H. u. a. (2025): https://dl.acm.org/doi/full/10.1145/3702652.3744219
[5] Fu, Yujia u. a. (2025): https://dl.acm.org/doi/full/10.1145/3716848
[6] Alenzi, Akour (2025): https://www.mdpi.com/2076-3417/15/3/1344
Bild-Quelle für Thumbnail: https://en.windowsnoticias.com/What-is-vibe-coding/